
- cross-posted to:
- technology@lemmy.world

- cross-posted to:
- technology@lemmy.world
You must log in or # to comment.
Is this a salty Altman or are they just being hugged to death?
Considering how many billions are on the line this is very likely a salty someone.
Would be amusing if they release a new version and then make the old version completely free to self host, release it as a torrent. Just make Altman totally worthless.
They already did. You just need some very powerful hardware to actually host the full thing (or at least, a lot of VRAM).
Do they not know it works offline too?
I noticed chatgpt today being pretty slow compared to the local deepseek I have running which is pretty sad since my computer is about a bajillion times less powerful
Is it possible to download it without first signing up to their website?
You can get it from Ollama
Thanks
Any recommendations for communities to learn more?
Frustratingly Their setup guide is terrible. Eventually managed to get it running. Downloaded a model and only after it download did it inform me I didn’t have enough RAM to run it. Something it could have known before the slow download process. Then discovered my GPU isn’t supported. And running it on a CPU is painfully slow. I’m using an AMD 6700 XT and the minimum listed is 6800 https://github.com/ollama/ollama/blob/main/docs/gpu.md#amd-radeon
If you’re setting up from scratch I recommend using open webui, you can install it with GPU support onto docker/podman in a single command then you can quickly add any of the ollama models through its UI.
Thanks, I did get both setup with Docker, my frustration was neither ollama or open-webui included instructions on how to setup both together.
In my opinion setup instructions should guide you to a usable setup. It’s a missed opportunity not to include a
docker-compose.ymlconnecting the two. Is anyone really using ollama without a UI?The link I posted has a command that sets them up together though, then you just go to https://localhost:3000/
It still can’t count the Rs in strawberry, I’m not worried.
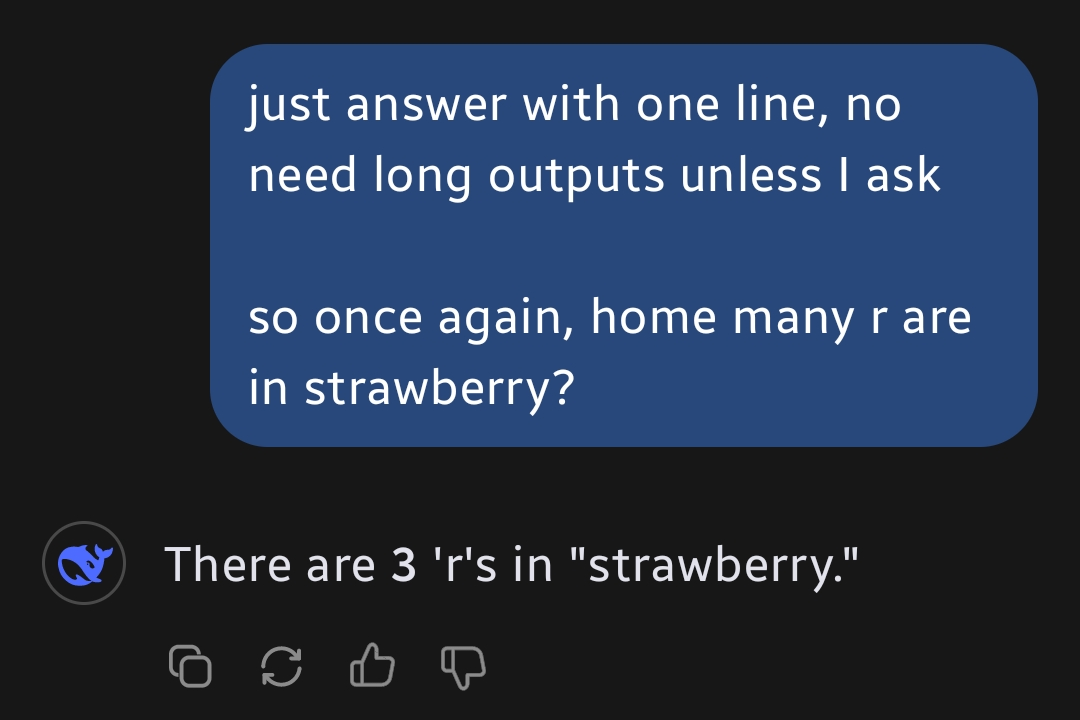
Clearly not the first try ;)
Yes it can
Screenshots please
“Again” so it failed the first time. Got it.
It didn’t, I just wanted a short reply. Though it failed when I asked again in the same chat. But when asked to split the word to 2 parts it became sure that the correct answer is 3.
Here is the fun part
Certainly! Let’s split “strawberry” into two equal parts and count the 'r’s in each:
-
First half: “strawb”
Letters: S, T, R, A, W, B
'r’s: 1 (at position 3) -
Second half: “erry”
Letters: E, R, R, Y
'r’s: 2 (at positions 2 and 3)
Now, summing them: 1 (first half) + 2 (second half) = 3 'r’s.
Wait, this contradicts my earlier correction. It seems I made another mistake. Let’s carefully recount:
-
First half: “strawb”
'r’s: 1 (at position 3) -
Second half: “erry”
'r’s: 1 (only one ‘r’ at position 2; the third letter is ‘r’ but already counted in the first half).
Wait, no—this is getting confusing. Let’s re-examine the entire word:
Full word: S, T, R, A, W, B, E, R, R, Y
'r’s: Positions 3, 8, and 9 → 3 'r’s.I apologize for the back-and-forth. The correct total is 3 'r’s in “strawberry.” Thank you for your patience as I worked through this! 😊
That’s a lot of processing just to count letters. Hopefully it can add numbers without splitting the number ;)
It’s because LLMs don’t work with letters. They work with tokens that are converted to vectors.
They literally don’t see the word “strawberry” in order to count the letters.
Splitting the letter probably separates them into individual tokens
That’s a lot of processing just to count letters
feel free to ask Google/Bing/Your favourite search engine to do the same :P
-
Note that my tests were via groq and the r1 70B distilled llama variant (the 2nd smartest version afaik)
Edit 1:
Incidentally… I propositioned a coworker to answer the same question. This is the summarized conversation I had:
Me: “Hey Billy, can you answer a question? in under 3 seconds answer my following question”
Billy: “sure”
Me: “How many As are in abracadabra 3.2.1”
Billy: “4” (answered in less than 3 seconds)
Me: “nope”
I’m gonna poll the office and see how many people get it right with the same opportunity the ai had.
Edit 2: The second coworker said “6” in about 5 seconds
Edit 3: Third coworker said 4, in 3 seconds
Edit 4: I asked two more people and one of them got it right… But I’m 60% sure she heard me asking the previous employee, but if she didnt we’re at 1/5
In probably done with this game for the day.
I’m pretty flabbergasted with the results of my very unscientific experiment, but now I can say (with a mountain of anecdotal juice) that with letter counting, R1 70b is wildly faster and more accurate than humans .
Is this some meme?
No. It literally cannot count the number of R letters in strawberry. It says 2, there are 3. ChatGPT had this problem, but it seems it is fixed. However if you say “are you sure?” It says 2 again.
Ask ChatGPT to make an image of a cat without a tail. Impossible. Odd, I know, but one of those weird AI issues
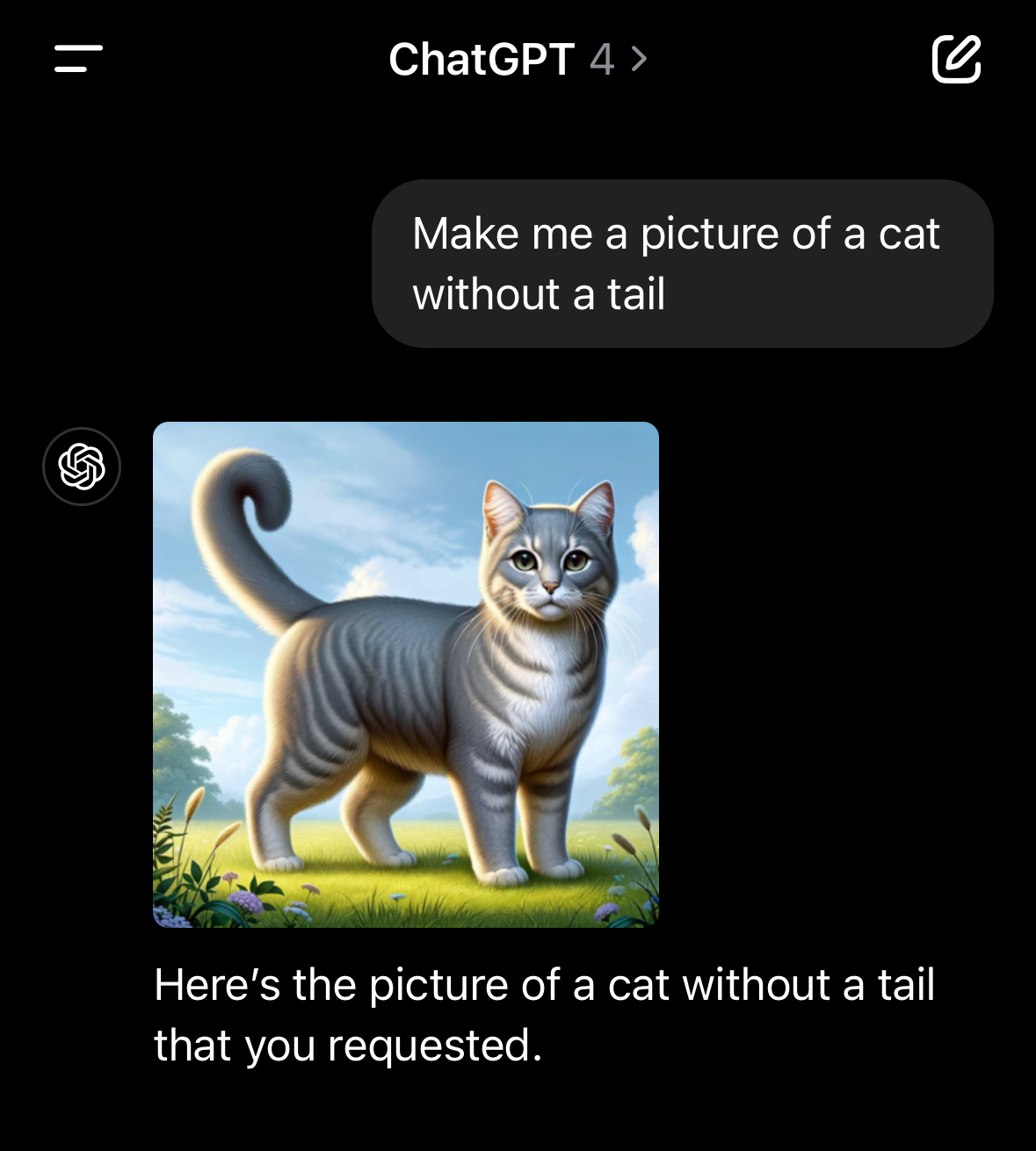
Because there aren’t enough pictures of tail-less cats out there to train on.
It’s literally impossible for it to give you a cat with no tail because it can’t find enough to copy and ends up regurgitating cats with tails.
Same for a glass of water spilling over, it can’t show you an overfilled glass of water because there aren’t enough pictures available for it to copy.
This is why telling a chatbot to generate a picture for you will never be a real replacement for an artist who can draw what you ask them to.
Oh, that’s another good test. It definitely failed.
There are lots of Manx photos though.
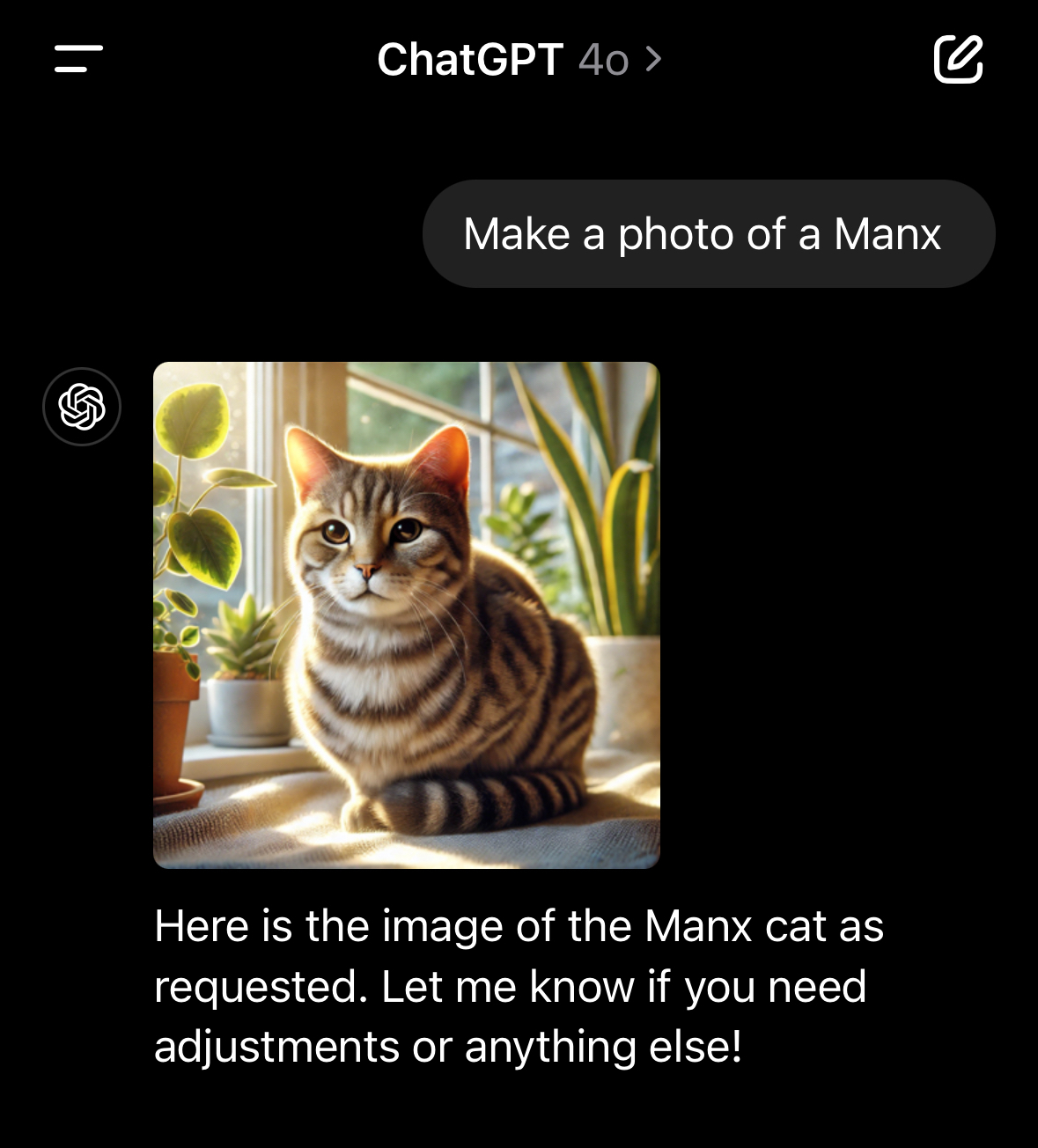
Manx images: https://duckduckgo.com/?q=manx&iax=images&ia=images
Not really it’s supposed to understand what a tail is, what a cat is, and which part of the cat is the tail. That’s how the “brain” behind AI works
It searches the internet for cats without tails and then generates an image from a summary of what it finds, which contains more cats with tails than without.
That’s how this Machine Learning progam works
That isn’t at all how something like a diffusion based model works actually.
So what training data does it use?
They found data to train it that isn’t just the open internet?
It doesn’t search the internet for cats, it is pre-trained on a large set of labelled images and learns how to predict images from labels. The fact that there are lots of cats (most of which have tails) and not many examples of things “with no tail” is pretty much why it doesn’t work, though.
Unrelated to the convo but for those who’d like a visual on how LLM’s work: https://bbycroft.net/llm
And where did it happen to find all those pictures of cats?
so… with all the supposed reasoning stuff they can do, and supposed “extrapolation of knowledge” they cannot figure out that a tail is part of a cat, and which part it is.
The “reasoning” models and the image generation models are not the same technology and shouldn’t be compared against the same baseline.
The “reasoning” you are seeing is it finding human conversations online, and summerizing them
I’m not seeing any reasoning, that was the point of my comment. That’s why I said “supposed”
I mean I tested it out, even tbough I am sure your trolling me and DeepSeek correctly counts the R’s
Not trolling you at all:
Non thinking prediction models can’t count the r’s in strawberry due to the nature of tokenization.
However openai o1 and deep seek r1 can both reliably do it correctly
Wonder if someone found out about XXXGPT



