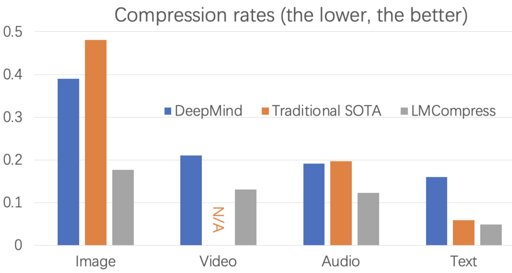
People store large quantities of data in their electronic devices and transfer some of this data to others, whether for professional or personal reasons. Data compression methods are thus of the utmost importance, as they can boost the efficiency of devices and communications, making users less reliant on cloud data services and external storage devices.

Trading processing power for size is a thing. I guess it depends on application and implementation. Well, and on the actual size of the models required.
It’s one of those things that makes for a good headline, but then for usability it has to be part of a whole conversation about whether you want to spend the bandwidth, the processing power on compression, the processing power on real time upscaling, the processing power on different compression tools, something else or a mix of the above.
I suppose at some point it’s all “benchmarks or it didn’t happen” for these things. And when it comes to ML benchmarks are increasingly iffy anyway.
But spending a lot of processing power to gain smaller sizes matters mostly in cases you want to store things long term. You probably wouldn’t want to keep the exact same LLM with the same weightings and stuff around in that case.